今回取り上げるspaCyというPythonの自然言語処理ツールですが、オンラインコースが英語と日本語で公開されている: https://course.spacy.io/ja もっと詳しく知りたい方はご活用下さい。
Internet
インターネットは世界中の複数の(コンピュータ)ネットワークを相互に繋いだネットワークである。インターネットはインターネット・プロトコル(IP)によりその機能が決められるが、ここでは主にHTTP(S)、IPアドレスとドメイン名(DNS)に着目する。
- https://tools.keycdn.com/tracerouteを使ってnlp.lang.osaka-u.ac.jpを入力(IPアドレスを特定後にIPアドレスを入力)
Web
Webは元々World Wide Web (WWW)として知られており、テキストやメディアファイルなどの資源にアドレスが付与されて資源の間でそのアドレスを参照することで相互にインターネットからアクセスできる情報システムである。 Webを観覧するソフトウエアクライアントはしばしばブラウザとなるが、実は他のクライアントも多数ある。 Googleなどの検索エンジンはユーザの要求(クエリ)に応えるためにWebをなす可能な限りすべてのページを観覧し、重要な情報を抽出している。スマフォのアプリはユーザに広告を見せるために、Webから画像を取得している等など、ブラウザとして認識難いシステムも存在するが、その基盤としてはWebになっていることが未だ多い。
HTML
HyperText Markup Language (HTML)はWebにおけるWebページを記述する基盤的な言語である。現在の一般的なWebページではHTMLとともにCSSとJavaScriptも一緒に使われている。 HTMLではページの内容、CSSではページの見た目、そしてJavaScriptではページのインターアクティブな部分をスクリプトできるものとして、役割が別れている。
HTMLの中で注目したいのはHyperTextという概念である。 HyperTextでTextを超えるという意味で、あるページから他のページへのリンク・関連付けができる仕組みを指している。普段ではリンクと呼ばれるものはこの議論の中でハイパーリンク(hyperlink)と置き換える。 WWWはこのような定義を踏まえて「インターネット上のハイパーテキストシステム」として説明できる。
基本的な見た目は以下の通り:
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<link rel="author" href="mailto:mail@example.com">
<title lang="en">HyperText Markup Language - Wikipedia</title>
</head>
<body>
<article>
<h1 lang="en">HyperText Markup Language</h1>
<p>HTMLは、<a href="http://ja.wikipedia.org/wiki/SGML">SGML</a>
アプリケーションの一つで、ハイパーテキストを利用してワールド
ワイドウェブ上で情報を発信するために作られ、
ワールドワイドウェブの<strong>基幹的役割</strong>をなしている。
情報を発信するための文書構造を定義するために使われ、
ある程度機械が理解可能な言語で、
写真の埋め込みや、フォームの作成、
ハイパーテキストによるHTML間の連携が可能である。</p>
</article>
</body>
</html>注意したいのはHTMLはXMLから始まった規格ではあるが、最近(HTML5)は正式にXMLの文法に則っていない部分がある。その理由は、最近のHTMLの規格はXMLのような厳密に書かれた文法より実際に世の中で使われているあらゆる間違いをも許すブラウザの中の仕組みに則っているということである1。
URLとURI
HTMLの例では、<a href="http://ja.wikipedia.org/wiki/SGML">SGML</a>のようなa要素の中のhrefがURLとなっている。 URLはすでにインターネットに慣れている人なら聞いたことがある・書いたことがあることが多いが、URIという用語との関係はわからない人は少なくないと推測できる。実はUniform Resource Identifier(URI)はURLの上位概念であり、見た目は同じである:
host port
┌──────┴──────┐ ┌┴┐
https://www.example.com:123/forum/questions/?tag=networking&order=newest#top
└─┬─┘ └──┬──────────────┘└───────┬───────┘ └───────────┬─────────────┘ └┬┘
scheme authority path query fragment一般的にschemeが省略されているときはhttpかhttpsを指す。 portは多くの場合schemeに規定さており、省略できる。 queryとfragmentもオプショナルであるが、fragmentについては標準的にHTMLページ内のidに紐付けられている。
Linked Open Data (LOD)
Linked Open DataはWeb上に構造化されたデータを共有する技術の総称である。 LODを可能にするのは幾つかの技術であるが、下記に簡単に列挙するとする:
- RDF: メタ情報のデータモデルであり、言語のSVOのような文の三つ組から出来ている:
<http://example.org/#spiderman> <http://www.perceive.net/schemas/relationship/enemyOf> <http://example.org/#green-goblin> .(subject, predicate, object) - 語彙: もの及びものの間の関係性をまとめたメタ情報で再利用を目的とすることが多い
- SPARQL: RDFをデータベースとしてクエリできる言語
例1
- LOD Challenge
- 受賞者など公開されている作品を検索してみよう
例2

まとめ
RDFなど個別のデータ間に関係性が記述されているデータベース、すなわち構造化されたデータがあれば、その検索・加工などは容易になる。 Webではすでに多くのそのよう構造化データ(Structured Data)が存在する。また、扱っている領域における概念間の関係性をRDFを始めとするデータ構造として記述すれば、構造化データとなる。構造化されたデータの得点は、その機械的処理により新しい価値(見方ないし他データとの連携など)を生み出すことができることにある。デメリットとしては、領域にもよるが、概念間の関係性を厳密に記述するために高度な専門知識が必要で、時にはその作業自体が研究に費やせる時間の多大な割合を締めてしまうことがある。そんなときには、データの構造化をしてくれるアルゴリズムとモデルを用いればその作業が多いに省略されることが可能であるが、未だAIで十分に解決できないものがある限り、その適応が限られる。
そこでテキストデータに秘めている構造を割り出す分野として自然言語処理が存在する。
自然言語処理(Natural Language Processing, NLP)
言語の曖昧性
- “I saw a girl with a telescope”の係り受け構造
- 状況により人間は2つの解釈から1つを選ぶが、自然言語処理のモデルは何をすればよい?
自然言語処理の概要・タスク
自然言語処理の広義では、言語情報を処理するということで、あらゆることが想像できる。
- 音声認識
- 特徴語の抽出
- 検索エンジン
- 構文解析
- 意味解析
- 機械翻訳
- 質疑応答
- …
上記のリストからは特徴語の抽出と検索エンジンは一般的にInformation Retrievalという分野で特に扱われているが、他の項目は恐らくみると自然言語処理に当たるものばかりと思われる。しかし、その一方では異なる言語情報(例えば音声データvsテキストデータ)を扱っているところで自然言語処理では様々な(サブ)タスクが存在し、それぞれのタスクで全く異なる手法と目的が存在する。今回は主にテキスト処理に限定し、しかも一般的に現実的に使えるツールに絞っている。特に意味解析など高度な言語理解はまだ解析が難しい研究段階である。一方では最近の計算のキャパシティの増加と深層学習やデータ収集の強化に伴い、昔難しいとされていたことが視野に入りつつある。
教師ありと教師なし学習
一般的な自然言語処理のタスクでは、アノテーションされたデータを対象に機械学習を行い、新たなデータでも同様なアノテーションが付与できるモデルを構築している。それは教師あり学習として分類され、アノテーションがないデータからその構造をモデル化する教師なし学習と対照している。一番簡単な例としては教師あり学習としては回帰モデルがあり、教師なし学習ではクラスター及び主成分解析がある。
教師あり機械学習を行う際に気をつけないといけないところは、過学習(過剰適合)という現象である。これは学習してきたデータ(訓練データ, training data)に対する精度が高い一方、新しいデータに対する精度が乏しいことである。そのためにはモデル学習を行う際に学習を行っていないデータ(評価データ, test set)を予め分けて用意し、それに対する精度で過学習を計測できる。
一般的なテキスト処理のパイプライン
spaCyのテキスト処理の流れを参考にそれぞれのステップについて簡単に説明する。 spaCyを一言で説明すると実用的な自然言語処理処理をPythonで行える便利且つ質の高いツール(ライブラリ)である。

Text
Textはここである文ないし文章を構成する文字列である。 spaCyでは文・パラグラフ・文章などの構造について概念として取り扱っているものは基本的に文のみであるので、パラグラフごとの処理・計算が必要だったらspaCyとは別処理が必要になる。ここでは文と文章が現れた時に”自然言語処理を行う”のようにダブルクオーテーションで囲む。それはPythonでは文字列は”“で囲まれるからである。
tokenizer
トーケン化する処理は、文にある文字列をそれぞれの言葉に分割する処理である。英語のように空白で単語が区切られている言語でも、記号処理・’sなど接頭辞の処理を行う必要がある。

tagger
タグ及び品詞付与処理は、トーケン毎にその品詞を推定することである。上記の例では以下のように解析される:
| Token | POS | Tag |
|---|---|---|
| ” | PUNCT | `` |
| Let | VERB | VB |
| ’s | PRON | PRP |
| go | VERB | VB |
| to | ADP | IN |
| N.Y. | PROPN | NNP |
| ! | PUNCT | . |
| ” | PUNCT | ’’ |
自然言語処理では品詞体系は基本的に言語毎(及びコーパス毎)に特化していたが、最近では言語横断的に自然言語処理の発展のためにUniversal Dependencies(UD)という試みがある。 spaCyのPOS情報はそれに準じているが、学習元となるコーパスのTagも情報として残している。最近はGiNZAという日本語版spaCyを使うと、日本語も同じように解析できる。
| Token | POS | Tag |
|---|---|---|
| ニューヨーク | PROPN | 名詞-固有名詞-地名-一般 |
| に | ADP | 助詞-格助詞 |
| 行こう | VERB | 動詞-非自立可能 |
| ! | PUNCT | 補助記号-句点 |
日本語に特化した品詞体系との対応についてはここをご参照下さい。英語と日本語の主な違いはここまでの処理に位置づけられるtokenizerは日本語の場合、日本語の空白を伴わない書記法の性質でその処理は一般的にtaggerと一緒に行われる。つまり、分かち書き処理を行う場合でも主流な日本語自然言語処理ツール(MeCab、Juman++、Sudachi)では品詞推定を同時に行っている。
parser
parserは計算工学ではある構文ルールを使って文字列からその構文に沿ったシンタックスツリーを作るという意味の用語であるが、spaCyの場合は様々な種類の構文解析の中で係り受け解析処理を示す。係り受け解析では、単語と単語の間の構文的な関係性を同定する解析であり、単語毎に係り先を1つ付与している。その意味は係り先が1つであるが、係り受け関係が0無いし複数あるということである。
先程の2例をそれぞれをspaCyとGiNZAで解析した結果が次の図:
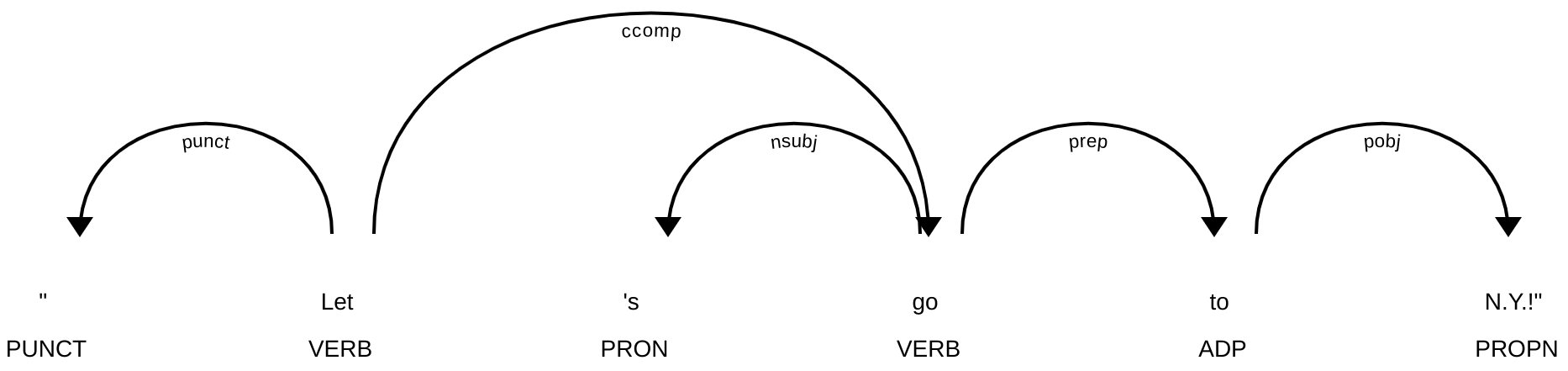
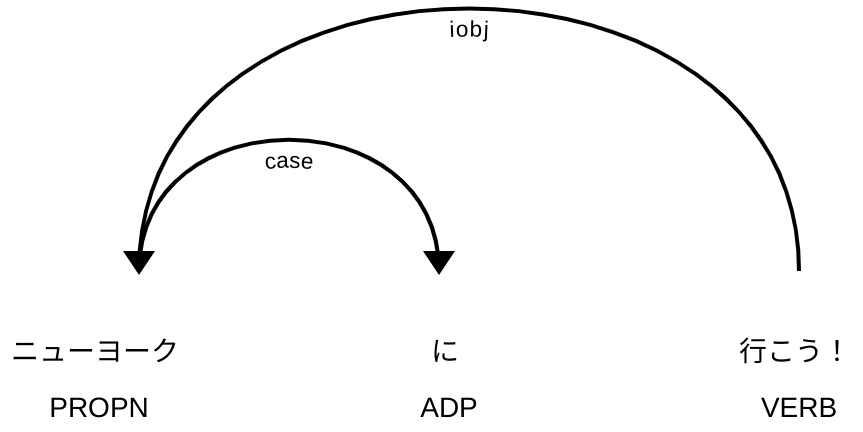
係り受け線では矢印が方向性を指し、線に沿っているラベルは係り受けの型(typed dependency)という。ここでの型の定義はUDの一覧をみると型ごとに説明と例がある。上記の型は:
punct: punctuation
ccomp: clausal complement
nsubj: nominal subject
prep: (*nmod:prep) prepositional modifier
pobj: object of preposition
case: case marking
iobj: indirect object
係り受け解析はspaCyのdisplacyというWebアプリを使うとわかりやすい。
ner
Named Entity Recognition (NER)は日本語で固有表現抽出と訳され、テキスト中から固有名詞(地名、氏名)や金額、時間に関する表現を抽出する。その範囲は単語ではないことが多くて、連続して出現する複数トーケンをまたがる単位として扱われている。 spaCyではOntoNotes 5というコーパスでアノテーションされている表現のタイプを提供している。 NERでは抽出したい表現のタイプがコーパスとタスク(目的)で異なるため、精度良く抽出したい場合は予め幾つかの固有表現アノテーション付き文を用意してNERのモデルを学習する必要がある。

displacyのNER版では入力して文章に対する固有表現を可視化できる。
vector
spaCyでいうvectorはWord Embeddings(分散表現ともいう)を指す。分散表現はそれぞれの語にベクトルを与えることで、語間の意味的な関係性を計算することができる。分散表現は単語を50–300次元の実数ベクトルとしてその意味を近似している。もう一つの特徴は、分散表現がなすベクトル空間においてその加法構成性を使いking - man + woman = ?のような問にベクトルの計算でqueenを割り出せる。
分散表現は単語の意味をある程度計算可能にするために、現在の多くの自然言語処理モデルの一部となっている。
- sense2vecは純粋な分散表現ではないが、Webアプリではおおよその精度を実感できる
API化されたWebサービスの普及
以上の例でspaCyを使ったWebアプリが何回かでてきた。自然言語の処理が実用的になりつつある中で、それを売り物とする会社も出てきている([1], [2])。それぞれのAPIは異なる仕組みと働きをしており、統一性はないが、spaCyでは実用的なクエリAPIとしてGraphQLを採用した:
Web上のサービスではJavaScriptのデータ保存と共有フォーマットであるJSONでクエリと結果が交わされることが多くて、RDFでもJSONで扱えるようにJSON-LDというスターンダードが(RDFの世界では)浸透してきている。いずれにせよ、自然言語処理ツールの出力を含め多くのデータはグラフ構造を持ち、それをどの規格でAPI化としても、そのデータの構造が十分に検索できることが望ましい。 RDFではなくとも、工夫でリレーショナル・データベース(SQL)でも検索できることが多い(場合にはリレーショナル・データベースはデータに一番適していることがある)。
ノートブック型プログラミング環境
インターアクティブなプログラミングやデータ解析を世界的に広く普及させたのがJupyter Notebookというソフトである。ブラウザからテキストからなら解説とデータ解析のコード、またはその結果を同じノートブックに表示することがメリットである。また、ノートブックをファイルとして保存し、他の研究者と共有させることで研究の再現性や2普及に多いに貢献してきた。
今回の一連の処理を自分でも実行できるノートブックを共有させた。 Jupyter NotebookではなくGoogle Colabというサービスでグーグルアカウントさえあれば無料でグーグルクラウドで仮想マシン上にノートブックでコードを実行できる。