オンラインコースが英語と日本語で公開されている: https://course.spacy.io/ja
デジタルヒューマニティーズA(言語処理と情報検索)オリエンテーション
Digital Humanities
デジタルヒューマニティーズは様々な定義ができるが,ここでは情報科学と人文科学の接点として
- 情報科学から自然言語処理,情報検索,データベース,可視化に
- 人文科学から言語学・近代日本語の文学を加え
学習するものとする。
青空文庫
今回の対象とする近代日本語の文学の多くのテキスト資料は青空文庫に公開されていて、それを加工すれば、自然言語処理及び書誌情報データベースの検索により膨大な研究資料となる。青空文庫の仕組みについてまだご存じない方は青空文庫の早わかりを読んでください。
自然言語処理
spaCy
本授業では自然言語処理の基本的なタスクをspaCyで処理する。
言語の曖昧性
- “I saw a girl with a telescope”の係り受け構造
- 状況により人間は2つの解釈から1つを選ぶが、自然言語処理のモデルは何をすればよい?
自然言語処理の概要・タスク
自然言語処理の広義では、言語情報を処理するということで、あらゆることが想像できる。
- 音声認識
- 特徴語の抽出
- 検索エンジン
- 構文解析
- 意味解析
- 機械翻訳
- 質疑応答
- …
異なる言語情報(例えば音声データvsテキストデータ)を扱っているところで自然言語処理では様々な(サブ)タスクが存在し、それぞれのタスクで全く異なる手法と目的が存在する。本授業では主にテキスト処理に限定し、しかも一般的に現実的に使えるツールに絞っている。特に意味解析など高度な言語理解はまだ解析が難しい研究段階である。一方では最近の計算のキャパシティの増加と深層学習やデータ収集の強化に伴い、昔難しいとされていたことが視野に入りつつある。
教師ありと教師なし学習
一般的な自然言語処理のタスクでは、アノテーションされたデータを対象に機械学習を行い、新たなデータでも同様なアノテーションが付与できるモデルを構築している。それは教師あり学習として分類され、アノテーションがないデータからその構造をモデル化する教師なし学習と対照している。一番簡単な例としては教師あり学習としては回帰モデルがあり、教師なし学習ではクラスター及び主成分解析がある。(spaCyのそれぞれの処理過程は教師あり学習を使用している。)
一般的なテキスト処理のパイプライン
spaCyのテキスト処理の流れを参考にそれぞれのステップについて簡単に説明する。 spaCyを一言で説明すると実用的な自然言語処理処理をPythonで行える便利且つ質の高いツール(ライブラリ)である。

Text
Textはここである文ないし文章を構成する文字列である。 spaCyでは文・パラグラフ・文章などの構造について概念として取り扱っているものは基本的に文のみであるので、パラグラフごとの処理・計算が必要だったらspaCyとは別処理が必要になる。ここでは文と文章が現れた時に”自然言語処理を行う”のようにダブルクオーテーションで囲む。それはPythonでは文字列は”“で囲まれるからである。
tokenizer
トーケン化する処理は、文にある文字列をそれぞれの言葉に分割する処理である。英語のように空白で単語が区切られている言語でも、記号処理・’sなど接頭辞の処理を行う必要がある。

tagger
タグ及び品詞付与処理は、トーケン毎にその品詞を推定することである。上記の例では以下のように解析される:
| Token | POS | Tag |
|---|---|---|
| ” | PUNCT | `` |
| Let | VERB | VB |
| ’s | PRON | PRP |
| go | VERB | VB |
| to | ADP | IN |
| N.Y. | PROPN | NNP |
| ! | PUNCT | . |
| ” | PUNCT | ’’ |
UD
自然言語処理では品詞体系は基本的に言語毎(及びコーパス毎)に特化していたが、最近では言語横断的に自然言語処理の発展のためにUniversal Dependencies(UD)という試みがある。 spaCyのPOS情報はそれに準じているが、学習元となるコーパスのTagも情報として残している。最近はGiNZAという日本語版spaCyを使うと、日本語も同じように解析できる。
| Token | POS | Tag |
|---|---|---|
| ニューヨーク | PROPN | 名詞-固有名詞-地名-一般 |
| に | ADP | 助詞-格助詞 |
| 行こう | VERB | 動詞-非自立可能 |
| ! | PUNCT | 補助記号-句点 |
parser
parserは計算工学ではある構文ルールを使って文字列からその構文に沿ったシンタックスツリーを作るという意味の用語であるが、spaCyの場合は様々な種類の構文解析の中で係り受け解析処理を示す。係り受け解析では、単語と単語の間の構文的な関係性を同定する解析であり、単語毎に係り先を1つ付与している。その意味は係り先が1つであるが、係り受け関係が0無いし複数あるということである。
先程の2例をそれぞれをspaCyとGiNZAで解析した結果が次の図:
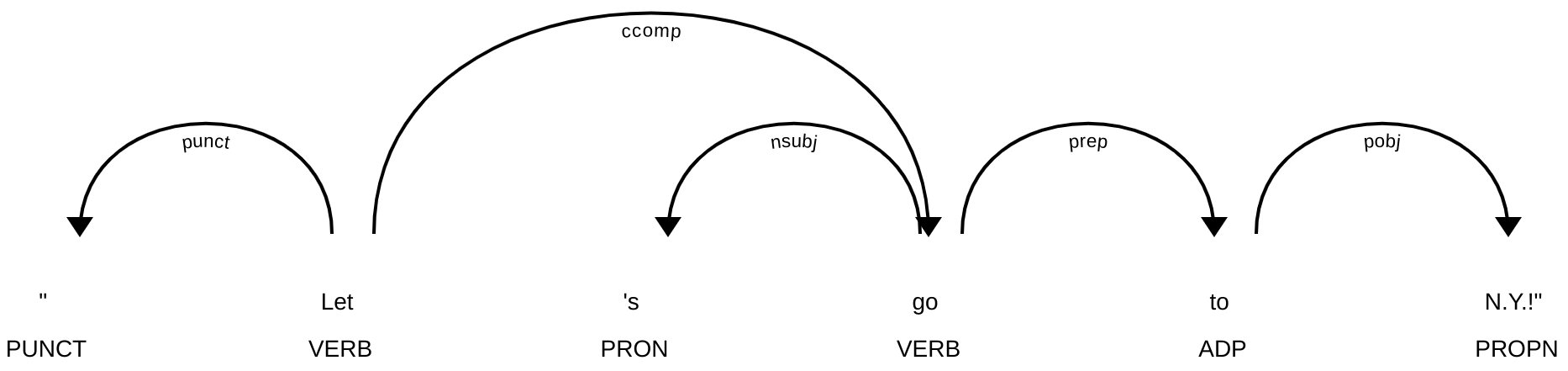
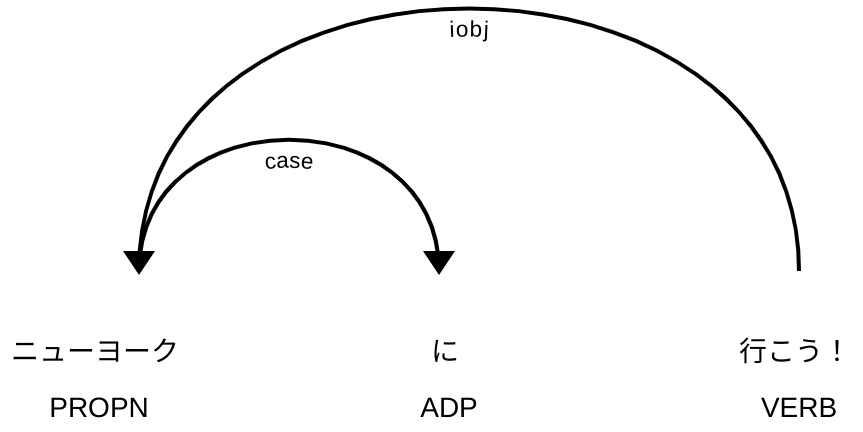
係り受け線では矢印が方向性を指し、線に沿っているラベルは係り受けの型(typed dependency)という。ここでの型の定義はUDの一覧をみると型ごとに説明と例がある。上記の型は:
- punct: punctuation
- ccomp: clausal complement
- nsubj: nominal subject
- prep: (*nmod:prep) prepositional modifier
- pobj: object of preposition
- case: case marking
- iobj: indirect object
係り受け解析はspaCyのdisplacyというWebアプリを使うとわかりやすい。
vector
spaCyでいうvectorはWord Embeddings(分散表現ともいう)を指す。分散表現はそれぞれの語にベクトルを与えることで、語間の意味的な関係性を計算することができる。分散表現は単語を50–300次元の実数ベクトルとしてその意味を近似している。もう一つの特徴は、分散表現がなすベクトル空間においてその加法構成性を使いking - man + woman = ?のような問にベクトルの計算でqueenを割り出せる。
分散表現は単語の意味をある程度計算可能にするために、現在の多くの自然言語処理モデルの一部となっている。
- sense2vecは純粋な分散表現ではないが、Webアプリではおおよその精度を実感できる
API化されたWebサービスの普及
以上の例でspaCyを使ったWebアプリが何回かでてきた。自然言語の処理が実用的になりつつある中で、それを売り物とする会社も出てきている([1], [2])。それぞれのAPIは異なる仕組みと働きをしており、統一性はないが、spaCyでは実用的なクエリAPIとしてGraphQLを採用した:
ノートブック型プログラミング環境
インターアクティブなプログラミングやデータ解析を世界的に広く普及させたのがJupyter Notebookというソフトである。ブラウザからテキストからなら解説とデータ解析のコード、またはその結果を同じノートブックに表示することがメリットである。また、ノートブックをファイルとして保存し、他の研究者と共有させることで研究の再現性や1普及に多いに貢献してきた。
本当に再現可能にするには、ノートブックのみではなくそこで使っているソフトすべてを何らかの形で保存する必要がある。↩︎