NLP with spaCy
Short overview of recent advances and preliminary notes on the 'Standard Ebooks' corpus
Bor Hodošček
2019/8/9
Introduction
- Two parts:
- Advances in NLP & spaCy
- Using spaCy to analyze an English ebooks corpus from the Standard Ebooks collection
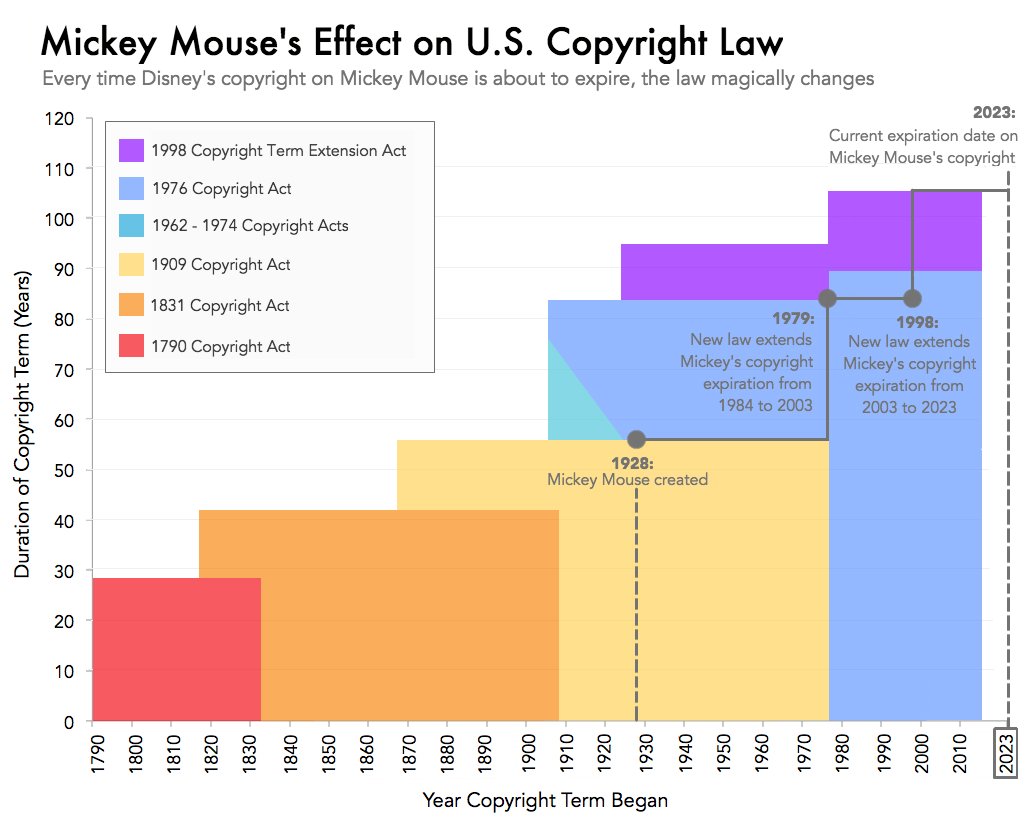
Motivation: recent news
Mickey Mouse and copyright in the US
Problems
- Many existing NLP tools for
- tokenization/POS-tagging: TreeTagger, Stanford CoreNLP, …
- dependency parsing: Stanford CoreNLP, CaboCha/KNP (Japanese), …
- named entity recognition: OpenNLP, …
- Break-neck pace of innovation in Deep Learning has trickled down to NLP: state-of-the-art (SOTA) models being released on what seems to be a monthly basis…
- Cutting-edge research models still mostly based on PyTorch or TensorFlow implementions, but some consolidation taking place (especially in dataset formats)…
NLP-progress
A site tracking progress across a variety of tasks (http://nlpprogress.com/).
SOTA in Word Representations
- (Language Modeling) Task: predict the next word in a sequence
- Task: predict words appearing next to word (*) or: predict word appearing within a span of words
Word Representation Methods
- Actually not “deep” learning:
- word2vec
- fasttext (also uses character n-grams)
- Learned from a window size (typically 5-8 tokens). Each word string is assigned a vector: does not disambiguate between different meanings of words.
- When you access the word representation, you do not make use of the surrounding context.
SOTA in *
“Muppets/Transformers-based”
- Predict (reconstruct) masked token from context
- ELMo: Deep contextualized word representations
![]()
- ELMo: Deep contextualized word representations
- Predict token from both left and right directions
- BERT: Bidirectional Encoder Representations from Transformers
![]()
![]()
- BERT: Bidirectional Encoder Representations from Transformers
- More advanced transformers: predict context word both forwards and backwards (not at the same time)
- Most implemented in HugginFace’s Pytorch-Transformers



GPT-2 Unicorn Example
System Prompt (human-written)
In a shocking finding, scientist discovered a herd of unicorns living in a remote, previously unexplored valley, in the Andes Mountains. Even more surprising to the researchers was the fact that the unicorns spoke perfect English.
Model Completion (machine-written, 10 tries)
The scientist named the population, after their distinctive horn, Ovid’s Unicorn. These four-horned, silver-white unicorns were previously unknown to science.
Now, after almost two centuries, the mystery of what sparked this odd phenomenon is finally solved.
Dr. Jorge Pérez, an evolutionary biologist from the University of La Paz, and several companions, were exploring the Andes Mountains when they found a small valley, with no other animals or humans. Pérez noticed that the valley had what appeared to be a natural fountain, surrounded by two peaks of rock and silver snow.
Pérez and the others then ventured further into the valley. “By the time we reached the top of one peak, the water looked blue, with some crystals on top,” said Pérez.
Pérez and his friends were astonished to see the unicorn herd. These creatures could be seen from the air without having to move too much to see them – they were so close they could touch their horns.
While examining these bizarre creatures the scientists discovered that the creatures also spoke some fairly regular English. Pérez stated, “We can see, for example, that they have a common ‘language,’ something like a dialect or dialectic.”
Dr. Pérez believes that the unicorns may have originated in Argentina, where the animals were believed to be descendants of a lost race of people who lived there before the arrival of humans in those parts of South America.
While their origins are still unclear, some believe that perhaps the creatures were created when a human and a unicorn met each other in a time before human civilization. According to Pérez, “In South America, such incidents seem to be quite common.”
However, Pérez also pointed out that it is likely that the only way of knowing for sure if unicorns are indeed the descendants of a lost alien race is through DNA. “But they seem to be able to communicate in English quite well, which I believe is a sign of evolution, or at least a change in social organization,” said the scientist.
spaCy
- Python library for NLP (from webpage:)
- Non-destructive tokenization
- Named entity recognition
- Support for 51+ languages
- 19 statistical models for 9 languages
- Pre-trained word vectors
- State-of-the-art speed
- Easy deep learning integration
- Part-of-speech tagging
- Labelled dependency parsing
- Syntax-driven sentence segmentation
- Built in visualizers for syntax and NER
- Convenient string-to-hash mapping
- Export to numpy data arrays
- Efficient binary serialization
- Easy model packaging and deployment
- Robust, rigorously evaluated accuracy
spaCy Models
- Pre-trained models for:
- 6 models: English (tagger, parser, ner, word embeddings, BERT, XLNet)
- 3 models: German
- 2 models: Greek, French, Spanish
- 1 model: Italian, Dutch, Portuguese
- No models, but integrates existing parsers/tools: Japanese (UniDic+MeCab), Chinese (jieba), Russian (pymorphy2), Ukrainian (pymorph2), Thai (pythainlp), Korean (mecab/natto-py), Vietnamese (Pyvi)
Spacy Intro
spaCy Extensions
- Easy to extend/build on (spaCy Universe)
- AllenNLP: An open-source NLP research library, built on PyTorch (and spaCy)
- NeuralCoref 4.0: Coreference Resolution in spaCy with Neural Networks
- scispaCy: spaCy models for processing biomedical, scientific or clinical text
- And many more…
Aside: Prodigy
- An annotation tool for AI, Machine Learning & NLP: NER, text classification, …
- Active learning (human in-the-loop) support
- (*)Commercial product from the makers of spaCy
GiNZA / spaCy for Japanese
- Currently a standalone tool that uses spaCy and SudachiPy (+UniDic), developed by Megagon Labs (formerly Rakuten Institute of Technology)
- Models trained on Japanese Universal Dependencies treebanks
- UD_Japanese-PUD: 1,000 sentences/2,6707 tokens (for testing)
- UD_Japanese-BCCWJ: 57,109 sentences/1,273,287 tokens (Japanese treebank among largest in UD)
- KWDLC (京都大学ウェブ文書リードコーパス): ~5k sentences
- (In comparison with the Kyoto Corpus 4.0: ~40k sentences, less annotations)
- Word vectors on Japanese Wikipedia
Standard Ebooks
“Free and liberated ebooks, carefully produced for the true book lover.”
- Aim to professionaly typeset and proofreed interesting out-of-copyright works
- Open source toolkit for ebook transformation/generation
- Adds metadata:
subjects, …
- Adds metadata:
Collection
- Currently 278 books
- Most metadata avaliable in XML feed
https://standardebooks.org/opds/ - Genre information is present in the form of LCSH (Library of Congress Subject Headings) labels (“Geographical myths – Fiction”, “Married women – Fiction”, “Frontier and pioneer life – Nebraska – Fiction”)
- More reader-friendly content available inside each ebook’s metadata (as
subject: “Fiction”, “Mystery”, “Shorts”)
- More reader-friendly content available inside each ebook’s metadata (as
Preliminary results (small model) Preliminary results (large model)
Git versioning
Full revision history for every book is on Github:
https://github.com/standardebooks/emile-gaboriau_the-lerouge-case/commit/50958e4ed3cc22cf9afb26dabcd93d9f986f9b8a
Issues with formatting and spaCy
- Most (English-language) parsers are trained on ASCII text, so some of the “advanced” punctuation usage used by Standard Ebooks is incorrectly segmented
- Unicode dash
―should be replaced with-(space dash space) or just-(dash)
- Unicode dash
- Real fix for these kinds of problems is to define a custom pipeline (to keep the text as-is)
- spaCy
Docobject is not meant for texts the size of books (you will run out of memory); best to use it at the paragraph level, as theDocobject has a notion of sentences, but not paragraphs
Thanks for listening
言文HP及びPCアルバイト募集中
- 言文専攻のホームページ(WordPress, HTML)編集
- 現在のリンク切れは…
- シラバス更新
- WindowsのOS構成設定とソフトのインストール作業など
- 無線LAN設定