英語電子書籍テキスト処理
‘Standard Ebooks’とspaCyを例に
Bor Hodošček
2022/2/4
イントロダクション
- 今日の話は2019年8月に本研究会で発表した“NLP with spaCy: Short overview of recent advances and preliminary notes on the ‘Standard Ebooks’ corpus”で開発した電子書籍パッケージを,最近の自然言語処理手法に当てるようにし,他のパッケージとの共存や多くの利用者のワークフローに干渉なく利用できるようにどのように開発を進めば良いかについて話す
- 最終目的は授業で利用できるコーパスとして使うこと
Standard Ebooks
“Free and liberated ebooks, carefully produced for the true book lover.”
Unicodeを惜しまないできれいにtypesettingをしているのが特徴
マニュアル及びプログラムによるチェックでEbookとしての統合性を図っている https://github.com/standardebooks/tools/blob/master/se/se_epub_lint.py
様々なメタ情報付与
- ジャンル情報はLCSH (Library of Congress Subject Headings)ラベルを採用 (“Geographical myths – Fiction”, “Married women – Fiction”, “Frontier and pioneer life – Nebraska – Fiction”)
- 「話題」を追加 (
subject: “Fiction”, “Mystery”, “Shorts”)
現時点で629件の電子書籍としてはGutenbergより小さい
開発目的
- デジタル・ヒューマニティーズ(A/B)授業のニーズに合わせ,適切な材料として使用できる
- すでにspaCyのオンライン授業が公開されているため,基本的にはそこで習ったものを今度電子書籍で実施できるように整備する
(目的1)spaCyとの独立性を重視
- spaCyではパイプラインという概念があり,基本的に下記図の
nlp前後(Text, Doc)のサポートが目的

- (日本語はパラレルに青空文庫をメインに別途準備しているため,今日の話は英語の電子書籍に限定する。ただし,ここで紹介する手法・例はspaCyがサポートする多くの言語で再現できる。)
(目的2)応用・検証
- 英語電子書籍テキストに合わせるためのspaCyの各パイプラインにカスタマイズが必要な場合はその対処法について紹介する
- DH研究でよく使用される手法とパッケージと干渉なく組み合わせできる
(目的3)メタ情報
- 電子書籍はそのテキストのみからなるものではなく,その周辺のメタ情報が重要なため,電子書籍のメタ情報と紐付けができつつ,電子書籍テキストにおけるspaCyの分析結果と組み合わせることにできる
- 電子書籍レベル以外も
- 文レベル:強調範囲 (“I didn’t mean to do it.”),固有名詞,他言語使用
- パラグラフレベル:パラグラフ内全文に関する内容(例えば:引用,など)
- 章・節など構造レベル:章番号,タイトルなど
- 著者属性,ジャンル,話題に関する情報
目的1:spaCyとの独立性を重視
- spaCyだけでなく,spaCyを囲むecosystemが日々進化するので,各種変化に柔軟に対応できるよう,spaCyをパッケージの依存パッケージにしない
- spaCyでは処理に使われるモデルとデータ量において最適なコードの書き方が異なる
- 研究目的で使用したい文章の区切りとspaCyの処理過程が干渉
(前回の2019年の発表から引用)Issues with formatting and spaCy
- Most (English-language) parsers are trained on ASCII text, so some of the “advanced” punctuation usage used by Standard Ebooks is incorrectly segmented
- Unicode dash
―should be replaced with-(space dash space) or just-(dash)(大幅に解消された)(tokenizerのカスタマイズ周りの説明もわかりやすくなった)
- Unicode dash
- Real fix for these kinds of problems is to define a custom pipeline (to keep the text as-is)(前回と比べカスタマイズできるところが増え,必ずしもパイプラインでなくてよい)
- spaCy
Docobject is not meant for texts the size of books (you will run out of memory); best to use it at the paragraph level, as theDocobject has a notion of sentences, but not paragraphs(nlp.pipeの導入である意味前より複雑になったこともいえる)
目的1:Standard Ebooksなど電子書籍を柔軟にも
- spaCyだけでなく,電子書籍も様々なところで作られている
- Gutenbergをはじめ,各種リソースが同じインターフェースで使えることが便利
- むしろ電子書籍の「整理機能」として充実させる
目的2:応用・検証
(目的2)検証:spaCy Universe
- spaCyを使った各種拡張パッケージで現在128リンクされている
- 一部spaCy 3に対応しないものとDHの一般的なテキスト処理とは関連が薄いものを除き,主に5パッケージを調査し,最終的に3つを本パッケージと組み合わせてみた
spaCy Universeパッケージ選別(1)
- https://github.com/HLasse/TextDescriptives “A Python library for calculating a large variety of statistics from text” 平均単語長,平均文長,品詞割合など簡単なテキスト集計
- https://github.com/samedwardes/spacytextblob “A TextBlob sentiment analysis pipeline component for spaCy” 元祖TextBlobのspaCy版
- https://github.com/MartinoMensio/spacy-sentence-bert “Sentence transformers models for SpaCy” 最先端の文トランスフォーマーモデルをspaCyで簡単に利用できる
spaCy Universeパッケージ選別(2)
https://github.com/brucewlee/lingfeat “LingFeat - A Comprehensive Linguistic Features Extraction ToolKit for Readability Assessment” spaCyを内蔵しているため,独自に処理してこのパッケージに渡すこと,他のパッケージと組み合わせにくい設計
https://github.com/dpalmasan/TRUNAJOD2.0 “A text complexity library for text analysis built on spaCy” スペイン語に焦点を当てているため今回は試していないが,目的がtext complexity analysisとして一番機能があるパッケージのようだった(→今後検証する)
(目的2)応用:spaCy Universeで選別したパッケージ
TextDescriptives
- TextDescriptivesはspaCyのDocかDocのリストを入力として,データフレームで各種の基礎集計結果を返すため,Standard Ebooksコーパスの最初10本を対象に,PCAで本単位と5000文字文単位で可視化してみた
- ノートブック
SpacyTextBlob
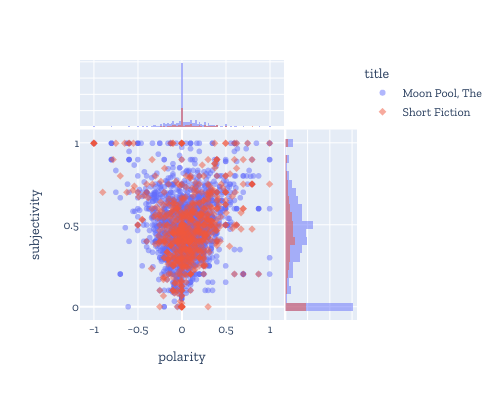
- SpacyTextBlobは利用者が準備したnlpオブジェクトに新しいパイプラインを追加することによって,spaCyで解析後のDocで拡張情報(doc._.XYZ)であるpolarity, subjectivity及びassessmentsを簡単にアクセスできる。
- Standard Ebooksコーパスの2本に対し,パラグラフごとにDocを整備し,polarityとsubjectivityを図化してみた
- ノートブック
spacy-sentence-bert
- spacy-sentence-bertはUPKLabのsentence transformersをspaCyで使用しやすくするためのものである
- sentence transformersは文,パラグラフ及び画像単位の使用目的に特化したトランスフォーマーモデルを提供していて,例えばコサイン距離で簡単に文と文の意味類似度が計算できる(従来の単語埋め込みモデルと違って,単語を単独ではなく,文章全体をコンテクストとして使用できる)
- Standard Ebooksコーパスで1本に対し,各章の意味類似度行列を計算し可視化した(理想的にはパラグラフなどより小さい単位)。続いて,sentence transformersのcommunity detectionクラスタ化手法を採用し,意味的に近いパラグラフのクラスタを発見し,動作を確認できた。最後に,ユーザが提示した言語クエリ(文)と意味的に一番近いパラグラフを取り出した。
- ノートブック
目的3:メタ情報
- 基本的なテキスト処理の部分を解消してから開発に挑む
- Standard EbooksはZ39.98-2012 Structural Semantics Vocabularyを採用しており,それを対象にパッケージ内から検索できるようにする
- 電子書籍の整理機能とも関係する
まとめ
- 目的1と2をある程度達成しているが,3方面でさらに検証が必要
- 特に現状では,3パッケージ(タスク)でしか使用していないため,パッケージのインターフェースは修正の必要性あり
おわりに
- 公開はGithub上,前期前に行う予定
- 授業で使用できる周辺の説明・課題でテストをし,改善していく
- Standard Ebooks以外の電子書籍の解析を検証
- 電子書籍をspaCyにかける前にsanity checkのようなものも行えるとよい(Unicodeでtokenizationが問題となるかどうか)